
2.2.6 퍼시스턴스 레이어 : 스프링 데이터 JPA
애플리케이션에서 데이터베이스 작업(테이블 생성, 엔트리 추가, 수정, 삭제)을 웹 서비스의 일부로 동작하게 하려면, 먼저 JDBC 드라이버가 필요하다.
JDBC 드라이버는 자바에서 데이터베이스에 연결할 수 있도록 도와주는 라이브러리로, 쉽게 말해 MySQL 클라이언트 같은 역할을 한다. 이를 통해 애플리케이션이 데이터베이스와 통신할 수 있다. MySQL 클라이언트도 내부에서 JDBC/ODBC 등의 드라이버를 사용한다.
// 데이터베이스 호출 예제
String sqlSelectAllTodos = "SELECT * FROM Todo WHERE USER_ID = " + request.getUserid();
String connectionUrl = "jdbc:mysql://mydb:3306/todo";
try {
// (1) 데이터베이스에 연결
Connection conn = DriverManager.getConnection(connectionUrl, "username", "password");
// (2) SQL 쿼리 준비
PreparedStatement ps = conn.prepareStatement(sqlSelectAllTodos);
// (3) 쿼리 실행
ResultSet rs = ps.executeQuery();
// (4) 결과를 객체로 파싱
while (rs.next()) {
long id = rs.getLong("id");
String title = rs.getString("title");
Boolean isDone = rs.getBoolean("done");
todos.add(new Todo(id, title, isDone));
}
} catch (SQLException e) {
// 예외 처리
e.printStackTrace();
}JDBC의 Connection 객체를 이용해 데이터베이스에 연결한 후, sqlSelectAllTodos에 작성된 SQL을 실행하면 ResultSet 객체에 결과가 저장된다. 이후, while 문 내부에서 ResultSet의 데이터를 가져와 Todo 객체로 변환한다.
이러한 과정은 객체(Object)와 관계형 데이터(Relation)를 매핑하는 작업이므로, 이를 **ORM(Object-Relational Mapping)**이라고 한다.
데이터베이스 테이블을 자바 내에서 사용하려면, 각 테이블마다 해당하는 엔티티(Entity) 클래스를 만들어야 한다. 예를 들어, MySQL의 Todo 테이블에 대응하는 TodoEntity.java 같은 엔티티 클래스가 존재한다.
또한, 이러한 ORM(Object-Relational Mapping) 작업을 집중적으로 처리하는 DAO(Data Access Object) 클래스도 필요하다. DAO 클래스는 특정 엔티티와 매핑되며, 보통 생성(Create), 검색(Read), 수정(Update), 삭제(Delete) 같은 기본적인 데이터베이스 연산을 담당한다.
이러한 작업은 테이블마다 반복적으로 이루어지는데, Hibernate 같은 ORM 프레임워크가 등장하면서 이 반복 작업을 줄일 수 있게 되었다. 더 나아가, JPA(Java Persistence API) 및 Spring Data JPA 같은 도구들이 개발되어 더욱 효율적으로 ORM을 처리할 수 있게 되었다.
**JPA(Java Persistence API)**는 데이터베이스 쿼리를 반복해서 작성하고 ResultSet을 직접 파싱해야 하는 개발자들의 부담을 줄여준다. JPA는 **스펙(Specification)**이며, "JPA를 구현하려면 이런 기능을 제공해야 한다"는 지침을 정의한 문서다. 즉, JPA는 데이터베이스 접근, 저장, 관리에 대한 표준 명세이며, 이를 따르기만 하면 내부 구현 방식은 자유롭다.
이 JPA 스펙을 실제로 구현하는 소프트웨어를 JPA Provider라고 하며, 가장 대표적인 JPA Provider가 Hibernate다.
스프링 데이터 JPA와 JPA의 관계
Spring Data JPA는 JPA + α로, JPA를 더욱 쉽게 사용할 수 있도록 도와주는 스프링의 프로젝트이다. 기술적으로 보면 Spring Data JPA는 JPA를 추상화(Abstraction)한 것이며, 추상화란 사용하기 쉬운 인터페이스를 제공하는 것을 의미한다. **Spring Data JPA에서 제공하는 인터페이스 중 하나인 JpaRepository**를 사용한다. JpaRepository를 활용하면, 기본적인 CRUD 기능을 직접 구현하지 않아도 자동으로 제공된다.
여기서 **"스프링 프로젝트(Spring Project)"**란 Spring Framework에서 제공하는 하나의 독립적인 하위 기술 또는 모듈을 의미한다.
스프링 생태계에는 다양한 하위 프로젝트가 존재하는데, 그중 하나가 Spring Data JPA다.
🔹 스프링 프로젝트(Spring Projects)의 개념
스프링은 단순한 프레임워크가 아니라, 여러 개의 모듈(프로젝트)로 이루어진 거대한 생태계이다.
- 각 프로젝트는 특정 기능을 담당하며, 독립적으로 사용될 수도 있고, 다른 스프링 기술과 함께 사용할 수도 있다.
- Spring Data JPA는 그중 하나로, **JPA를 더 쉽게 사용할 수 있도록 도와주는 모듈(프로젝트)**이다.
🔹 주요 스프링 하위 프로젝트 예시
- Spring Framework → 핵심 프레임워크 (DI, AOP 등)
- Spring Boot → 애플리케이션 개발을 간편하게 해주는 프로젝트
- Spring MVC → 웹 애플리케이션 개발을 위한 프로젝트
- Spring Security → 인증/인가를 위한 보안 관련 프로젝트
- Spring Data → 데이터베이스와의 연동을 쉽게 만들어주는 프로젝트
- Spring Data JPA → JPA를 더 쉽게 사용할 수 있도록 도와주는 프로젝트
🔹 결론
Spring Data JPA는 스프링 생태계 내의 하나의 프로젝트로, JPA를 더 편리하게 사용할 수 있도록 제공되는 모듈이다.
즉, Spring이 직접 개발한 JPA Provider는 아니지만, JPA를 쉽게 활용할 수 있도록 추상화한 라이브러리라고 보면 된다.
데이터베이스와 스프링 데이터 JPA 설정
runtimeOnly 'com.h2database:h2'H2는 In-Memory 데이터베이스로, 로컬 환경에서 메모리상에 데이터베이스를 구축해준다.
H2를 사용하면 별도의 데이터베이스 서버를 설치하거나 설정할 필요 없이 간편하게 DB를 사용할 수 있으므로, 초기 개발 및 테스트 환경에서 많이 활용된다.
build.gradle에 H2를 디펜던시로 추가하면, @SpringBootApplication 어노테이션을 통해 스프링이 자동으로 H2 데이터베이스에 연결해준다.
이때 H2를 기본 설정(In-Memory 모드)으로 실행하면
- 애플리케이션 실행 시 테이블이 생성되고,
- 애플리케이션 종료 시 테이블과 데이터가 함께 소멸된다.
즉, 애플리케이션이 실행되는 동안만 유지되는 임시 데이터베이스로 동작한다.
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'스프링 데이터 JPA를 사용하려면 spring-boot-starter-jpa 라이브러리가 필요하다.
이 라이브러리는 JPA 기능을 제공하며, Hibernate(기본 JPA Provider)를 포함하고 있어 별도로 설정할 필요 없이 JPA를 사용할 수 있도록 도와준다.
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v3.4.2)
Bootstrapping Spring Data JPA repositories in DEFAULT mode.
Finished Spring Data repository scanning in 18 ms. Found 0 JPA repository interfaces.
HikariPool-1 - Starting...
HikariPool-1 - Added connection conn0: url=jdbc:h2:mem:21d018bd-3966-4c03-bec3-cbbc68d1552d user=SA
HikariPool-1 - Start completed.
HHH000204: Processing PersistenceUnitInfo [name: default]
HHH000412: Hibernate ORM core version 6.6.5.Final애플리케이션 실행 로그를 보면 h2가 연결된다. JPA가 생성되었다는 사실, JPA Provider로 Hibernate ORM을 사용한다는 것, 그리고 애플리케이션이 H2 데이터베이스를 사용한다는 사실을 확인할 수 있다.
**참고 : Hibernate 6.x부터는 다이얼렉트(Dialect)를 자동 감지하는 기능이 강화되었으며, 일부 버전에서는 관련 로그가 출력되지 않을 수 있다.
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Data
public class TodoEntity {
private String id; // 이 오브젝트의 아이디
private String userId; // 이 오브젝트를 생성한 사용자의 아이디
private String title; // Todo 타이틀(예: 운동하기)
private boolean done; // true - todo를 완료한 경우(checked)
}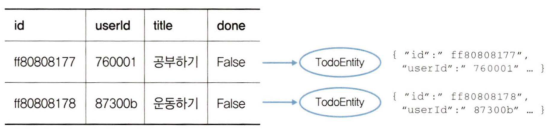
보통 데이터베이스 테이블마다 그에 상응하는 엔티티(Entity) 클래스가 존재한다. 따라서 우리 프로젝트에서는 **Todo 테이블에 상응하는 TodoEntity**가 존재한다.
하나의 엔티티 인스턴스는 **데이터베이스 테이블의 한 행(Row)**에 해당하며, 데이터베이스의 각 레코드를 자바 객체로 매핑하여 다룰 수 있도록 한다.
엔티티 클래스는 클래스 자체가 테이블을 정의해야 한다. 즉, **ORM(Object-Relational Mapping)**이 엔티티를 보고 해당 테이블의 어떤 필드에 매핑해야 하는지를 알 수 있어야 한다는 뜻이다. 또한, 어떤 필드가 기본 키(Primary Key)인지, 외래 키(Foreign Key)인지도 구분할 수 있어야 한다. 이러한 데이터베이스 테이블 스키마 정보는 javax.persistence 패키지가 제공하는 JPA 관련 어노테이션을 사용하여 정의한다.
엔티티 클래스를 정의할 때는 몇 가지 주의해야 할 점이 있다. 첫 번째로, 매개변수가 없는 기본 생성자(NoArgsConstructor)가 필요하다. 두 번째로, 필드 값을 조회하거나 변경할 수 있도록 Getter/Setter 메서드가 있어야 한다. 세 번째로, 반드시 기본 키(Primary Key)를 지정해야 한다.
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Data
@Entity
public class TodoEntity {
private String id; // 이 오브젝트의 아이디
private String userId; // 이 오브젝트를 생성한 사용자의 아이디
private String title; // Todo 타이틀(예: 운동하기)
private boolean done; // true - todo를 완료한 경우(checked)
}자바클래스를 엔티티로지정하려면 TodoEntity에 @Entity를 추가해야한다. 엔티티에 특정 이름을 부여하고 싶다면, **@Entity(name = "TodoEntity")**처럼 매개변수를 넣어 지정할 수 있다.
테이블 이름을 지정하려면 @Table(name = "Todo") 어노테이션을 추가하면 된다. 이렇게 하면 해당 엔티티가 데이터베이스의 Todo 테이블에 매핑된다는 의미가 된다. 만약 @Table을 추가하지 않거나 name을 명시하지 않으면,
- @Entity(name = "엔티티이름")이 있다면, 해당 이름을 테이블 이름으로 사용한다.
- @Entity에 이름을 지정하지 않으면, 클래스의 이름을 테이블 이름으로 사용한다.
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Data
@Entity
@Table(name="Todo")
public class TodoEntity {
@Id
@GeneratedValue(strategy = GenerationType.UUID)
private String id; // 이 오브젝트의 아이디
private String userId; // 이 오브젝트를 생성한 사용자의 아이디
private String title; // Todo 타이틀(예: 운동하기)
private boolean done; // true - todo를 완료한 경우(checked)
}@Id는 엔티티의 기본 키(Primary Key)로 사용할 필드에 지정한다. 우리의 경우, id가 기본 키이므로 id 필드 위에 @Id 어노테이션을 추가해야 한다. 기본 키 값은 객체를 데이터베이스에 저장할 때마다 직접 생성할 수도 있지만, @GeneratedValue 어노테이션을 사용하면 자동으로 생성되도록 설정할 수도 있다.
** 참고 : Spring Boot 3 및 Hibernate 6에서 @GenericGenerator가 deprecated되면서 UUID를 사용할 때 @GeneratedValue(generator = "system-uuid") 같은 방식은 더 이상 유효하지 않다. 대신 @UUIDGenerator 또는 @GeneratedValue(strategy = GenerationType.UUID)를 사용하면 된다.
@Repository
public interface TodoRepository extends JpaRepository<TodoEntity, String> {
}JpaRepository는 인터페이스이며, 이를 사용하려면 새로운 인터페이스를 작성하고 JpaRepository를 **확장(extend)**해야 한다. 이때, JpaRepository<T, ID>는 제네릭(Generic) 타입을 받는다.
- 첫 번째 매개변수 T는 테이블에 매핑될 엔티티 클래스이다.
- 두 번째 매개변수 ID는 해당 엔티티의 기본 키(Primary Key) 타입이다.
예를 들어, TodoEntity의 기본 키 타입이 String이라면 JpaRepository<TodoEntity, String> 형태로 선언해야 한다. 또한, 해당 인터페이스의 상단에는 @Repository 어노테이션이 추가되는데, 이는 @Component의 특별한 케이스로서 스프링이 자동으로 빈으로 등록하고 관리하도록 한다.
@Service
public class TodoService {
@Autowired
private TodoRepository repository;
public String testService() {
// TodoEntity 생성
TodoEntity entity = TodoEntity.builder()
.title("My first todo item")
.build();
// TodoEntity 저장
repository.save(entity);
// TodoEntity 검색
TodoEntity savedEntity = repository.findById(entity.getId()).get();
return savedEntity.getTitle();
}
}여기서 직접 Entity 생성했는데, 이렇게 사용하면 안된다.
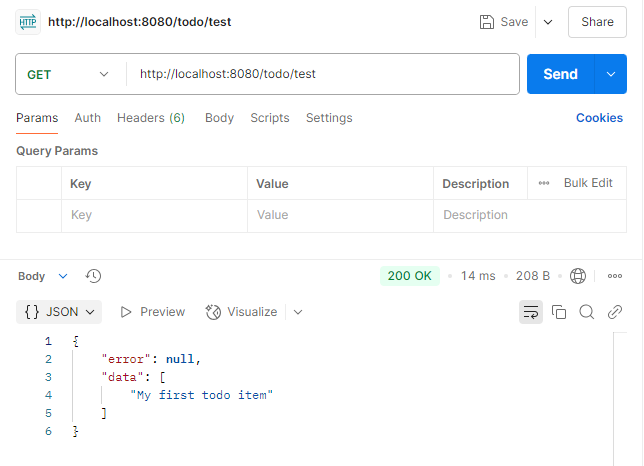
http://localhost:8080/todo/test를 실행하면 Service에서 작성한 "My first doto item"이 객체로 들어간다.
@NoRepositoryBean
public interface JpaRepository<T, ID>
extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
// 기본 조회 메서드
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
// 저장 관련 메서드
<S extends T> List<S> saveAll(Iterable<S> entities);
<S extends T> S saveAndFlush(S entity);
void flush();
// 삭제 관련 메서드
void deleteInBatch(Iterable<T> entities);
void deleteAllInBatch();
// 특정 ID로 엔티티 조회
T getOne(ID id);
// Query By Example (QBE) 조회 메서드
<S extends T> List<S> findAll(Example<S> example);
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}JpaRepository 인터페이스 내부를 들여다보면 JpaRepository는 기본적인 데이터베이스 연산을 수행할 수 있는 인터페이스를 제공한다. save, findById, findAll과 같은 메서드가 기본적으로 제공되며, 이러한 기능의 구현은 Spring Data JPA가 실행 시 자동으로 처리한다. 따라서 save 메서드를 직접 구현하기 위해 "INSERT INTO ..." 같은 SQL 쿼리를 작성할 필요 없이, Spring Data JPA가 내부적으로 이를 처리해준다.
TodoRepository는 인터페이스인데도 구현 클래스 없이 동작하는 이유는 Spring Data JPA가 내부적으로 JpaRepository의 메서드를 동적으로 구현해주기 때문이다.
보통 인터페이스나 추상 클래스는 반드시 구현 클래스가 있어야 하지만, Spring Data JPA에서는 그 법칙이 적용되지 않는다.
이를 이해하려면 AOP(Aspect-Oriented Programming, 관점 지향 프로그래밍) 개념을 알아야 한다.
🔹 Spring Data JPA가 JpaRepository를 실행하는 과정
- Spring AOP의 MethodInterceptor 인터페이스 사용
- Spring은 **AOP의 MethodInterceptor**를 활용해 JpaRepository의 메서드 호출을 가로챈다.
- 메서드 이름을 기반으로 동적 쿼리 생성
- 메서드를 호출하면, Spring이 메서드 이름을 분석하여 자동으로 적절한 SQL 쿼리를 생성한다.
- 예를 들어, findByTitle(String title)이라는 메서드가 있다면, Spring Data JPA는 이를
SELECT * FROM todo WHERE title = ?로 변환하여 실행한다.
3. 실제 데이터베이스 접근 및 실행
- 이렇게 생성된 쿼리는 Hibernate 같은 JPA Provider를 통해 실행되며, 결과를 반환한다.
즉, Spring AOP와 MethodInterceptor를 활용하여 JpaRepository의 메서드 호출을 가로채고, 메서드 이름을 기반으로 적절한 SQL 쿼리를 동적으로 생성하여 실행하는 방식으로 동작한다. 이러한 원리 덕분에 우리는 구현 클래스를 직접 작성하지 않고도 JpaRepository를 사용할 수 있다.
@Repository
public interface TodoRepository extends JpaRepository<TodoEntity, String> {
List<TodoEntity> findByUserId(String userId);
}findByUserId 메서드를 TodoRepository에 작성하면, Spring Data JPA가 메서드 이름을 분석하여 자동으로 SQL 쿼리를 생성한다. 이렇게 하면 별도의 SQL 작성 없이
SELECT * FROM Todo WHERE userid = '{userid}'와 같은 쿼리가 실행된다.
메서드 이름은 SQL 쿼리의 WHERE 조건을 자동으로 생성하며, 매개변수는 쿼리의 WHERE 절 값으로 사용된다. 더 복잡한 쿼리가 필요한 경우, @Query 어노테이션을 사용하여 직접 지정할 수도 있다.
@Repository
public interface TodoRepository extends JpaRepository<TodoEntity, String> {
// ?1은 메서드의 매개변수의 순서 위치이다.
@Query("SELECT * FROM TODO t WHERE t.userID = ?1")
List<TodoEntity> findByUserId(String userId);
}메서드 이름 작성 방법과 예제는 다음 공식 사이트의 레퍼런스를 통해 확인할 수 있다.
JPA Query Methods :: Spring Data JPA
By default, Spring Data JPA uses position-based parameter binding, as described in all the preceding examples. This makes query methods a little error-prone when refactoring regarding the parameter position. To solve this issue, you can use @Param annotati
docs.spring.io
메서드 이름 작성 방법과 예제는 다음 공식 레퍼런스를 통해 확인할 수 있다.
2.2.7 정리
레이어드 아키텍처 패턴, REST API, JPA 등 Spring Boot를 이용해 웹 서비스를 구현하는 데 필요한 개념을 학습하고 실습했다. 레이어드 아키텍처를 적용하여 패키지를 model, dto, persistence, service, controller로 나누었으며, 각 레이어는 저마다의 역할을 수행했다.
- 퍼시스턴스 레이어는 데이터베이스와 통신하며, 필요한 쿼리를 실행하고 결과를 해석하여 엔티티 객체로 변환하는 역할을 한다.
- 서비스 레이어는 HTTP나 데이터베이스 같은 외부 컴포넌트로부터 추상화되어, 개발자가 비즈니스 로직에만 집중할 수 있도록 했다.
- 컨트롤러 레이어는 HTTP 요청과 응답을 처리하며, 외부와의 통신 규약을 정의하는 역할을 담당한다.
'React.js, 스프링 부트, AWS로 배우는 웹 개발 101' 카테고리의 다른 글
| [Error] JPQL 문법 오류 (0) | 2025.02.17 |
|---|---|
| [TIL] 25/02/16, 서비스 개발 및 실습(1) (0) | 2025.02.17 |
| [TIL] 25/01/28, Service Layer : Business Logic (0) | 2025.01.29 |
| [TIL] 25/01/27, REST API (0) | 2025.01.28 |
| [TIL] 25/01/26, 백엔드 서비스 아키텍처 (0) | 2025.01.26 |